
單點故障(Single point of failure, SPOF),指的是系統上的某一個物理節點故障,而導致整個系統無法運作的現象。
當進行系統風險評估時,必需將單點故障造成的影響,列入評估的範圍。依單點故障發生,會造成服務中止或系統全面性故障,冗餘機制的設定就必定列入考量。
案例
在軟體系統開發上,常用在檢視與評估系統或網路架構的脆弱環節。
假設有一個 API 服務,服務本身需要面對高頻率的資料存取,其中有七成以上的請求,都是取得最近的公告資訊。
基於以上的情境,規劃的系統架構如下,若是請求 API 的種類與公告資訊相關。API 的處理流程是先嘗試到 Cache 取得資料,若 Cache 內沒有資料,再去訪問資料庫,並將取回的資訊放一份在 Cache 內。
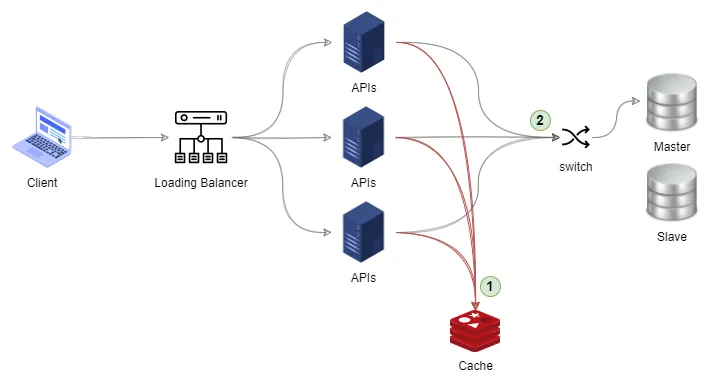
服務的系統架構初步看起來好像沒有問題,仔細觀察,發現所有的 API 主機同時使用同一台 Cache,這個節點的發生故障或異常,可能造成服務中止。
當 Cache 主機發生異常,或是遭遇到快取雪崩、快取擊穿、快取穿透等極端問題時,將會產生海量的請求直接繞過 Cache 衝擊資料庫。這極可能造成資料庫癱瘓,進而導致系統全面掛點。因此,在上述架構中,這台單點的 Cache 主機就是 SPOF。
那實務上該如何「排除」這個單點故障呢?常見的做法是引入冗餘機制,例如將單節點的 Cache 升級為 Redis Cluster 或引入 Sentinel 架構來達成高可用性;或者在應用程式內先加一層 Local Cache(如 In-Memory Cache),形成多層級快取防禦,確保外部元件倒下時,系統仍有最後一道防線。
在清楚有那些節點故障時,會對系統造成異常後,才能在事前安排對應的處理方式,達到防範於未然。
💡 互動時間 在你的職涯中,遇過最慘烈的 SPOF 災難是什麼呢?是某台沒人敢碰的老舊 Router 壞掉,還是全公司唯一的那台 DB 無預警重開?跟我們分享你的血淚史吧!
💬 留下你的想法
有問題、不同看法,或是你踩過類似的坑?歡迎留言討論,我會盡量回覆。